
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pre trained model
- activation function
- transfer learning
- vggnet
- ImageNet
- Anaconda
- pycharm
- Backbone network
- ReLU
- Today
- Total
Image 초보의 개발 공부
[논문 리뷰] VGGNet (Very Deep Convolutional Networks for Large-Scale Image Recognition) 논문 리뷰 본문
[논문 리뷰] VGGNet (Very Deep Convolutional Networks for Large-Scale Image Recognition) 논문 리뷰
고누놀이 2022. 10. 4. 16:28https://arxiv.org/abs/1409.1556
VGGNet 은 2014년 Imagenet Challenge에서 준우승을 차지한 모델이다. 1등은 GoogLeNet이 가져갔지만 모델이 간결하고 사용이 편리해 각광받았다. 개인적인 생각으로 구글은 왜 이렇게 뭐든 어렵게 하는지...Tensorflow도 TPU도...
Abstract

VGGNet의 논문 Abstract에서 소개하듯 VGGNet은 depth를 늘림에 따라 모델의 정확도가 영향받는 것을 조사한 것이다. convolution filter를 매우 작게(3x3) 만들어 depth를 늘렸다고 한다.
Introduction
Introduction에서 본 model이 출품된 ILSVRC의 소개와 함께 Abstract와 같이 논문의 방향에 대해 설명하고 있다.

구조의 parameter 중 3x3 convolution filter를 모든 layer에 사용함으로 layer를 늘리면서도 정확도를 올렸다고 한다.
결과적으로 비교적 간단한 pipeline들을 사용하면서도 ILSVRC의 국한된 자료뿐 아니라 다른 image recognition에서도 ConvNet 구조가 더욱 정확해졌다고 한다.
ConvNet Configurations
이제 본격적으로 VGGNet의 구조를 설명한다.

1. Architecture
학습에는 224 x 224의 고정된 RGB image를 사용했다. 전처리로는 오로지 각 pixel에 대해 RGB 평균값을 빼는 것만 했다. 구조는 다음을 따랐다.
- 좌우/상하/중앙의 정보를 다 담을 수 있는 가장 작은 kernel size인 3 x 3 receptive field 사용
- 한 configuration에선 선형 transformation을 위해 1x1 convolution filter도 활용
- Stride: 1 pixel
- padding: 1 pixel for 3x3 conv.layers
- Max pooling: (2x2 windows), stride=2
Fully Connected layers는 3개 layers를 사용했으며 첫 2 layers에선 4096 channels 마지막 layer에선 1000 channel을 이용했다.
모든 hidden layer에선 ReLU 함수를 사용했다. 또한 한 configuration을 제외하고선 Local Response Nomalization(LRN)을 사용하지 않았는데 이유로는 성능에는 영향이 없으며 메모리 소비와 계산 시간만 높인다고 사용하지 않았다 한다.
2. Configurations
이들은 구조를 조금씩 바꿔가며 A부터 E까지 6개의 configuration을 만들었다. convolution layer의 두께는 처음엔 64에서 max pooling을 거치며 2배씩 늘어 종단엔 512에 다다랐다.
또 더 깊은 depth를 가짐에도 불구하고 더 얕고 conv.layers width가 큰 network에 비해 weight의 개수가 적다는 것을 강조했다.
3. Discussion
중요한 것이 여기부터이다. 그들이 3 x 3 convolution layer를 강조하는 이유는 무엇일까?
우선, 하나의 큰 conv.layer(7x7)을 사용하는 것보다 세 개의 작은 conv.layer를 사용하는 것이 결정 함수를 더 성능 좋게 만들었다.
또, parameter의 개수를 크게 줄였다. 이들은 3 3x3 layers와 7x7 layer와 비교했는데 3개의 3x3 layers의 parameter 개수는 $3*(3*3*C^2) = 27C^2$개인데 7x7 layer는 $7*7*C^2 = 49C^2$개로 약 81% parameter수가 증가했다.
기존에도 작은 크기의 convolution filter를 사용하는 network(Ciresan et al., 2011)가 있었지만 VGGNet처럼 deep 하게 만들거나 ILSVRC의 큰 dataset을 사용하지는 않았다. 또 본 논문처럼 deep 하게(22 layer) 만든 모델도 있었지만(GooGleNet) VGG보다 복잡했다.
Classification Framework
1. Training
본 모델은 다음과 같은 알고리즘으로 모델을 학습시켰다.
- optimising the multinomial logistic regression objective
- mini-batch gradient decent
- batch size = 256
- momentum = 0.9
- L2 penalty multiplier = $5*10^(-4)$
- init learning rate = $10^(-2)$ (조정 가능)
- 370,000 iterations (74 epochs)
Weight initailization
나쁜 initialization은 네트워크의 안정성을 떨어뜨려 학습이 길을 잃어버리게 만드므로 네트워크의 weight를 초기화시켜주는 것은 매우 중요하다.
이 문제를 피하기 위해 연구자들은 다음의 과정을 사용했다.
- 학습하기에 충분히 얕은 모델을(configureation A) random initialization(정규분포를 따르는)과 함께 학습했다.
- 그리고 더 깊은 구조를 학습했고 첫 4개의 conv.layers와 마지막 3개의 fully connnected layer를 net A의 것으로 초기화했다.
Training image size
이들은 image의 가장 작은 part도 포함하는 image크기가 224x224라고 생각했기 때문에 학습하는 image의 크기를 224로 고정했다. 따라서 전체 image를 224x224로 crop 하여 사용했다.
이들이 image 크기를 결정하는 접근 방식이 두 가지라고 한다.
첫째*single-scale은 image scale을 고정한 것이다. 그들은 fixed scale로 256과 384 두 가지를 생각했다. 256은 image 분야에서 두루 자주 쓰이는 scale 사이즈이다. scale = 384 network의 학습 속도를 올리기 위해 scale = 256의 weight를 이용했으며 learning rate는 $10^(-3)$으로 초기화시켰다.
둘째*multi-scale은 scale을 고정하지 않고 일정 범위[256~512] 내에서 랜덤으로 정하는 것이다. 이렇게 함으로써 data augmentation을 이뤄 이점을 취할 수 있다. 속도를 위해 scale =384의 모델을 사용했다고 한다.
2. Testing
Testing 과정에서 마지막 fully-connected layer는 convolutinal layer로 바꾸어 test 했다.
또 첫 Fully connected layer는 7x7로 마지막 두 Fully connected layer는 1x1로 이를 fully-convolutional net이라 칭했다.
모든 이미지에 대해 fully-convolutional net이 적용됐기에 불필요한 계산을 줄이기 위해 test에는 multi crop을 진행할 필요가 없었다.
3. Implementary details
-생략-
Classification Experiments
1. Single Scale Evaluation

Single test scale 결과 망이 깊어질수록 더 좋은 결과가 나왔다.
본문에서는 3x3 conv.layer 두 개가 5x5 conv.layer 한 개의 망보다 7% 더 정확했다고 한다.
즉, convolution kernal의 크기를 줄이고 더 deep 하게 만드는 것이 parameter의 수를 줄여 계산량을 줄이는 것뿐 아니라 model의 non linearity를 늘려 feature 추출 성능이 더 좋아졌다는 것을 의미한다.
2. Multi-scale evalution

이번엔 Scale을 변화시켜 test를 진행시켰다. train scale과 test scale의 편차가 너무 크면 성능이 너무 떨어져서 test scale의 범위는 {S-32, S, S+32} (S=training scale)로 정하였다.
결과적으로 이전처럼 deep한 모델에서 더 좋은 성능을 내었고 scale jittering(multi-scale 적용)을 한 결과가 더 좋게 나왔다.
3. Multi-crop evalution

4. ConvNet Fusion
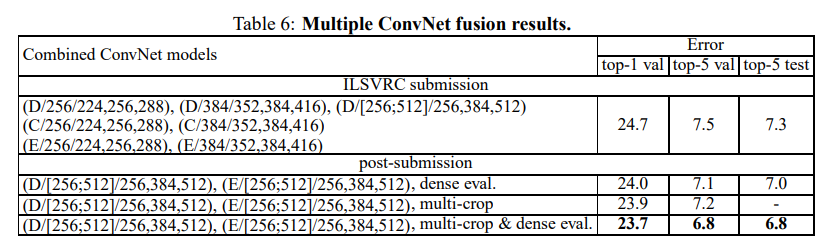
Conclusion
결론적으로 본 논문의 모델 VGGNet은 매우 deep 한 모델이 높은 정확도를 보이는 방법을 제시했다. 또한 large scale의 image dataset에서 좋은 결과를 보였으며 Imagenet dataset에서 좋은 퍼포먼스를 보였다.
Discussion 고찰
VGGNet은 최초로 인공지능이 인간의 판단력만큼의 성능을 낸 모델이다. 내가 느끼기에 가장 크게 와닿은 것이 모델을 더 deep하게 만들기 위해 기존과 다른 접근방식을 사용했다는 것이다. 이제는 꽤나 대중적인?방식이 되었지만 convolution map을 작게 만들어 모델을 deep하게 만든 접근방식이 신선하게 다가왔다.
'AI Tech' 카테고리의 다른 글
| Transfer Learning(전이 학습) (0) | 2022.09.02 |
|---|---|
| Activation Function (0) | 2022.09.02 |

